|
|
Data Science Updates is the University of Wisconsin-Madison's resource for news, training, events, and professional opportunities in data science, brought to you by the Data Science Institute, powered by American Family Insurance, and the Data Science Hub.
December 11, 2024
|
|
|
|
Happy Holidays!
Data Science Updates wishes all our readers a happy holiday season! This is our last issue of 2024. Our next issue will land in your inbox January 8.
|
|
|
|
Nexus Winter Challenge: Share ML/AI Resources and Win Prizes!
Since launching in summer 2024, Nexus has quickly grown to feature 40 ML/AI resources in total — thanks, contributors! While this number is an impressive milestone, we'd love to see additional ML/AI practitioners contribute and fully leverage Nexus for their own needs/purposes. To incentivize additional contributions over winter, we are thrilled to offer a $50 Amazon gift card to whoever contributes the greatest number of resources by February 3rd. This is only intended as an extra incentive, as the real prize is helping to build a stronger, more connected community of ML/AI practitioners on campus!
Contribution guidelines: Any content (original or external) that can help make the practice of AI/ML more connected, accessible, efficient, and reproducible is welcome on the platform. Visit the How to Contribute page for detailed guidance on contributing. If you’re unsure about the scope (most submissions are accepted) or have other questions—please contact endemann@wisc.edu. You're also welcome to stop by during ML+Coffee to ask questions (TODAY, Discovery building, Rm. 1145, 9-11am). Looking forward to your contributions as we grow Nexus together!
|
|
|
|
Learn Fundamental Research Computing Skills
Software Carpentry
January 13-16, 9:00 a.m. - 1:00 p.m.; Zoom. Software Carpentry aims to help researchers get their work done in less time and with less pain by teaching research computing skills. This hands-on workshop will cover introductory concepts and tools, including program design, version control, data management, and task automation teaching tools such as the Unix shell, git/GitHub, and Python. This workshop is for beginners wanting to get started using these tools and requires no prerequisite knowledge. Register for the workshop on the Software Carpentry workshop website.
|
Health Sciences Data Carpentry
January 21-24, 9:00 a.m. - 1:00 p.m.; Zoom. Data Carpentry teaches fundamental data skills needed to conduct research. This workshop is aimed at Health Science researchers, teaching how work with data from project organization in spreadsheets, to data cleaning with OpenRefine, to data analysis with SQL and R, and data visualization in R. This workshop is for beginners wanting to get started using these tools and requires no prerequisite knowledge. Register for the workshop on the Health Sciences Data Carpentry workshop website.
|
|
|
|
Trustworthy ML/AI – Explainability, Bias, Fairness, and Safety
December 16 - 18, 9:00 a.m. - 1:00 p.m.; Zoom. Join us for a free pilot of our new workshop, Trustworthy AI – Explainability, Bias, Fairness, and Safety. This lesson equips participants with trustworthy AI/ML practices, focusing on fairness, explainability, reproducibility, accountability, and safety across structured data, NLP, and computer vision tasks. Participants will learn to evaluate and enhance model trustworthiness and integrate ethical practices into research applications. As this is a pilot workshop, we’re looking for participant feedback to refine the lesson for future sessions.
The course is aimed at graduate students and other researchers at UW-Madison. Participants must have experience using Python and a basic understanding of machine learning (e.g., familiar with the concepts like train/test split and cross-validation) and should have trained at least one model in the past. To be added to the registrant list, email endemann@wisc.edu.
|
|
|
|
Tuesday Office Hours with Shared Tools
December 17, 10:30 a.m. - 11:30 a.m.; Zoom. Join the DoIT Help Desk at their office hours where they host office hours for their services: Jira, Confluence, and GitLab. During these office hours DoIT will answer questions about the discontinuation of DoIT Jira and Confluence Services, discuss best practices for migrating off Jira and Confluence, and help with data exports and imports to other services or cloud instances of Atlassian products. DoIT can also provide static copies of your Confluence spaces and answer general questions and discuss any GitLab needs. For more information, visit the Tuesday Office Hour calendar posting or visit the DoIT Shared Tools - Office Hours webpage.
|
|
|
|
Have questions about anything data science-related? Come see the Data Science Hub facilitators at Coding Meetup on Thursdays from 2:30-4:30 p.m. CT. To join Coding Meetup, join data-science-hubgroup.slack.com
|
|
|
|
SILO: Theory for Diffusion Models Theory for Diffusion Models
TODAY December 11, 12:30 p.m. - 1:30 p.m; Wisconsin Institute for Discovery, Orchard room 3280 + Zoom. Prof. Sitan Chen from Harvard will survey his team's recent efforts to develop a rigorous theory for understanding diffusion generative modeling. First, he will discuss discretization analyses that prove that diffusion models can approximately sample from arbitrary probability distributions provided one can have a sufficiently accurate estimate for the score function. Next, he will cover new algorithms for score estimation that, in conjunction with the results in the first part, imply new bounds for learning Gaussian mixture models.
|
|
|
|
ML+Coffee
TODAY December 11, 9:00 a.m. - 11:00 a.m.; Discovery Building, Room, 1145. Hosted by the ML+X community, the monthly ML+Coffee social brings together machine learning (ML) practitioners across campus so that we can connect with one another, discuss and work on ML projects, and enjoy some caffeinated refreshments. Attendees are encouraged to bring their laptops and/or any questions about ML.
|
|
|
|
Research Cyberinfrastructure (RCI) Cloud community meeting
December 18, 3:30 p.m. - 4:30 p.m.; Zoom. DoIT Research Cyberinfrastructure (RCI) is organizing a cloud community group, a platform that offers you the opportunity to gain and share valuable cloud computing skills. By joining this community, you’ll share your experiences using cloud resources and be part of a collective effort to understand the growing importance of cloud computing and to identify the latest cloud technologies. This community has already facilitated the creation of a panel on ‘Harnessing the Cloud for Data Science’ at the Research Bazaar, and has seen two of its members present at the 8th Annual UW–Madison IT Professionals Conference, sharing insights on building a cloud community at UW–Madison.
|
|
|
|
Present Your Work at the Data Science Research Bazaar
Apply by January 15 - Researchers, students, and professionals at all levels of expertise are invited to showcase their work at the 6th annual Data Science Research Bazaar, March 19-20 at the Discovery Building. This interdisciplinary conference welcomes submissions for data-science-focused lightning talks, posters, workshops, and interactive discussions.
This year’s theme is AI and ML in Research: Navigating Opportunities and Boundaries, and we welcome presentations that explore both the potential and limitations of artificial intelligence (AI) and machine learning (ML) in research. While AI/ML will be a key focus, we encourage submissions from all areas of fundamental and applied data science and computational work.
The Research Bazaar is an opportunity to connect with, learn from, and contribute to UW–Madison’s ever-expanding data science research community. Learn more and apply on the Data Science Research Bazaar webpage.
|
|
|
|
Administrative Assistance / Web Design
Apply by December 15 - The Chemical and Biological Engineering department is seeking a WordPress developer with Elementor experience. The student in this role will using Elementor to design and develop visually appealing websites that are responsive and functional. The student will also managing the website, resolve technical and content issues, and customizing existing themes and plugins to enhance functionality. To apply and learn more, visit the job posting on the Student Jobs page.
|
CHTC Fellows Program for Summer 2025
Apply by December 20 - The Center for High Throughput Computing (CHTC) Fellows Program trains undergraduate and graduate students in the development and use of cyberinfrastructure through a summer program where participants will work with mentors on delivering a project that will make an impact on the nation’s science. The projects provide exciting and challenging opportunities for students interested in software development, infrastructure services, or research facilitation. Fellows work with a mentor to develop a project relevant to one of these areas. To view the program description and to apply, visit the CHTC Fellows Program webpage.
|
|
|
|
|
2025 National Big Data Health Science Student Case Competition
|
|
|
|
Apply by January 29 - The University of South Carolina's Big Data Health Science Center is hosting their 6th annual Student Case Competition, a virtual event in which students compete in teams to solve an issue in healthcare using big data analytics for a chance to win cash prizes. The Big Data Health Science Student Case Competition is intended to provide enthusiastic teams of graduate and senior undergraduate students with the opportunity to apply their knowledge to analyzing big datasets in health care.
Each participating team will analyze the case and datasets to be released on Friday, February 7th, 2025, at noon EST. Through February 9th, team members will work together to present their methods, analyses, and results at the Big Data Health Science Center Case Competition virtually. A panel of industry and academic experts will judge the presentations based on each team’s use of full analytics tools/processes, from framing the problem to data use, model building, innovation, and communicating the solutions to decision-makers. View the flyer for more details about this event.
|
|
|
|
Data Integration and Warehouse Engineer
Apply by December 29 - The School of Medicine and Public Health, Informatics and Information Technology Collaborative is seeking a data Integration and Warehouse Engineer to develop, maintain, and troubleshoot data integrations, primarily in Informatica Cloud (IICS), and support multiple database systems. The person in this role works closely with their data analysts, developers, system administrators, and external partners to help direct the flow of data and ensure consistency for multiple needs. This includes consulting on and supporting the availability of this data to their data visualization platform, applications, websites, and other reporting projects.
This person coordinates with System Operations for backups, patches, and upgrades, is expected to establish and maintain effective working relationships with data leaders and administrators from UW campus and UW Health, and collaborates across the breadth of SMPH IT. For more information and to apply, view the job posting from School of Medicine and Public Health.
|
|
|
|
New Research Topics: NVIDIA Academic Grant Program Accepting Proposals
Apply by December 31 - NVIDIA’s Academic Grant Program is calling for research proposals to advance work in three new interest areas: Data Science, Graphics and Vision, and Edge AI. NVIDIA will continue accepting submissions for projects related to Simulation and Modeling and Gen AI and LLMs. For more information, please see the NVIDIA FAQs webpage.
New areas of interest:
- Data science submissions can include data processing, operational research and route optimization, and graph neural networks
- Graphics and vision submissions can include augmented and virtual reality, ray tracing, rendering, and AI for graphics
- Edge AI submissions can include robotics, autonomous vehicles, 5G/6G, smart spaces, and federated learning
|
|
|
|
Faculty positions open at Harvard Biostatistics/Dana-Farber Cancer Institute
Tenure-Track Professor of Artificial Intelligence/Machine Learning (AI/ML)
Tenure-Track Professor of Single Cell Genomics
Lecturer & Director of Training and Education
The successful candidate will be responsible for developing training curricula for a team of master's-level statisticians and computational biologists, including topics related to clinical trials, statistical modeling and inference, and genomics analysis. They will also create a continuing education program, online resources, and teach workshops. To learn more and apply, visit the job posting from the Dana-Farber Cancer Institute's Department of Data Science.
|
|
|
|
|
|
|
DATA VISUALIZATION OF THE WEEK
|
|
|
|
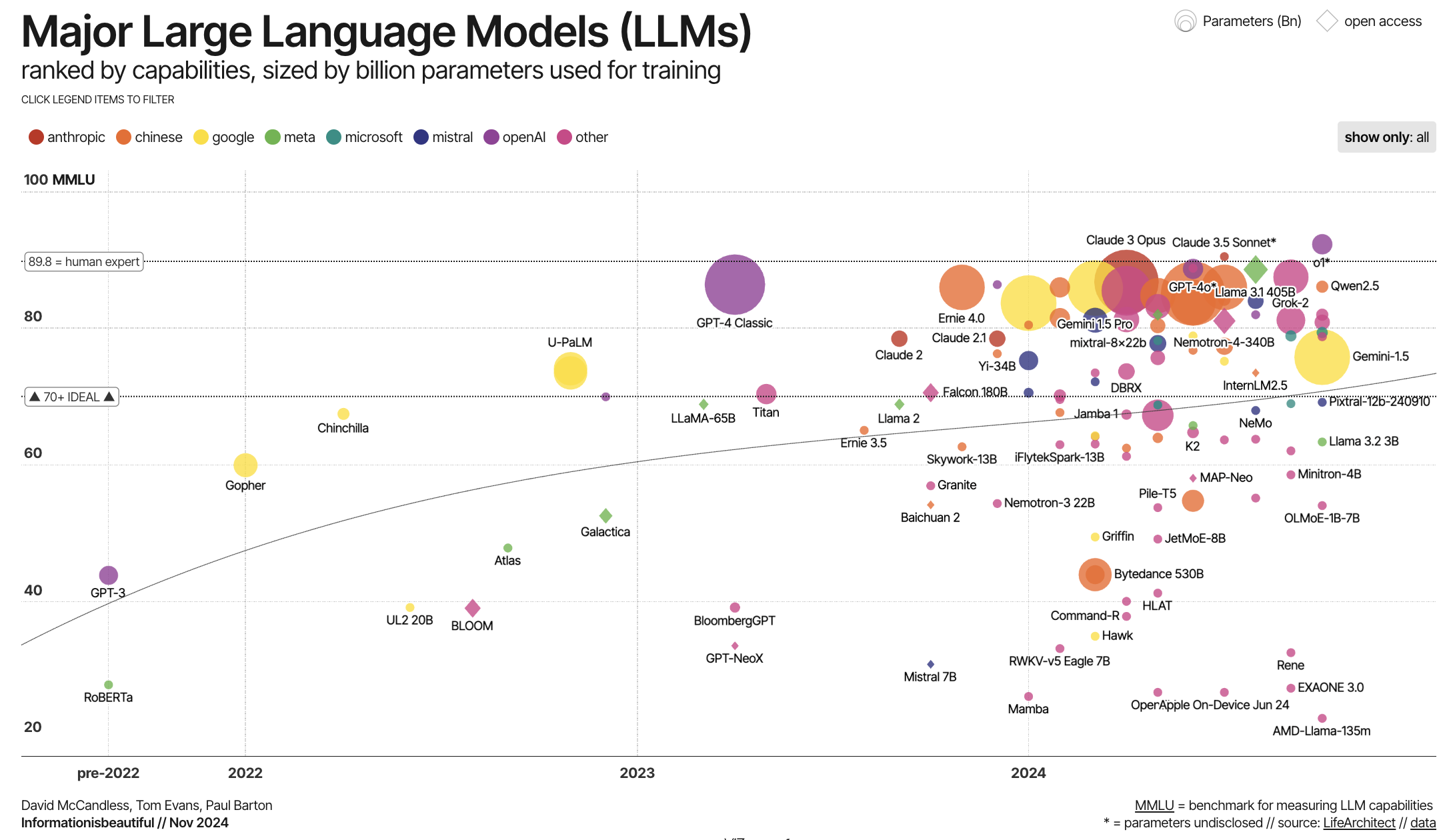
Major Large Language Models (LLMs) ranked by capabilities, sized by billion parameters used for training
Below is a visualisation created by David McCandless, Tom Evans, and Paul Barton of major large-language models (LLMs), ranked by performance. The visualization uses Massive Multitasks Language Understanding (MMLU) a benchmark for evaluating the capabilities of large language models. The MMLU rating consists of 16,000 multiple-choice questions across 57 academic subjects. However, MMLU has some critiques, mainly that LLM creators may be wise to the metric and be pre-training their models to answer MMLU questions.
|
|
|
|
Data Science Updates is a collaborative effort of the Data Science Institute and Data Science Hub.
Use our submission form to send us your news, events, opportunities and data visualizations for future issues.
|
|
|
|
|