|
|
Data Science Updates is the University of Wisconsin-Madison's resource for news, training, events, and professional opportunities in data science, brought to you by the Data Science Institute, powered by American Family Insurance, and the Data Science Hub.
January 22, 2025
|
|
|
|
Welcome Back to Data Science @ UW
This winter and spring, Data Science @ UW is offering an abundance of opportunities to build your data science skills and network with others who share your interests, including seminars, workshops, coding meetups, the Data Science Research Bazaar, data science communities of practice, student organizations, and more. This newsletter and the Data Science @ UW website provide the latest news about data science happenings on campus and in the community. Read on to learn about new workshops, the Data Story Slam, and other opportunities!
|
|
|
|
Share a Story, Hear a Story at the Data Story Slam
The Data Story Slam is an informal social held in conjunction with the 2025 Data Science Research Bazaar. Everyone’s life is impacted by data, and this event is an opportunity to share and hear stories of ordinary to extraordinary moments where life intersects with data. The Data Story Slam is open to all, and refreshments will be provided. Visit the Data Story Slam website to learn more and RSVP.
|
|
|
|
Research Cyberinfrastructure Community of Practice
Curious about what campus tools are available to help you with your research computing? Researchers and IT/support staff are invited to participate in this monthly community of practice, which features presentations and support related to campus research tools and services. At the online series kick-off on January 23rd at 1:00 p.m., the Research Cyberinfrastructure (RCI) team from DoIT will present an overview of the tools and services they support: data storage (ResearchDrive, Research Object Storage), Electronic Lab Notebooks (LabArchives), data transfer (Globus), data analysis and report/dashboard publication (Data Science Platform), and cloud computing. Learn more at the RCI Community of Practice meeting calendar listing.
|

|
|
|
|
The Patent Revolution: AI’s Impact on Intellectual Property
AI is transforming the intellectual property landscape, and you’re invited to explore its impact at The Patent Revolution: AI’s Impact on Intellectual Property, a free two-day event at the UW-Madison Memorial Union on February 4–5, 2025. The event kicks off at 9:00 a.m. each day and features expert discussions, networking opportunities, and a special student-focused session. A highlight of the agenda is “AI in IP: Is it Really You?” on February 4 from 11:00 a.m. to 12:00 p.m., led by Molly Kocialski, Regional Director of the USPTO’s Rocky Mountain Regional Outreach Office. With over 20 years of experience in intellectual property at companies like Oracle and Qwest, Molly brings deep expertise to the discussion on how AI is reshaping originality and identity in IP. Don’t miss this opportunity to connect with leaders and peers as we delve into the challenges and opportunities AI brings to the world of innovation. Visit the Patent Revolution webpage to learn more and register.
|
|
|
|
Data Visualization in R: ggplot2 Basics
January 28, 10:00 a.m. - 12:00 p.m.; 3218 Sewell Social Sciences. This data visualization workshop will teach you how to create and modify data visualizations using ggplot2, a popular plotting package in R. Emphasis is placed on using plots to understand distributions of different numbers and types of variables.
|
|
|
|
Excel 1: Introduction to Data Processing with Excel
January 30, 5:30 p.m. - 7:00 p.m.; 2257 College Library. This workshop is an introduction to working with data in Excel. Students will learn spreadsheet terminology, the basics of the Excel interface, how to create and edit spreadsheets, and how to generate charts and graphs from data. The workshop will cover many topics, including: navigating the Excel environment; entering and editing data; using formulas and functions; charting; and viewing, sorting, and filtering data. To learn more and register, visit the Excel 1: Introduction to Data Processing with Excel calendar listing.
|
|
|
|
R Programming: R Basics
January 31, 10:00 a.m. - 12:00 p.m; Zoom. The Libraries will be providing R and Python workshops during the spring 2025 semester. The first workshop is for the absolute beginner wanting to slowly walk through the process of getting started with R, a programming language commonly used for data analysis. The session will introduce you to the RStudio interface for coding in R. We will work through setting up a project directory, cover key concepts and terminology, and load and inspect a dataset. For more information, to register, and view the spring semester schedule, visit the Steenbock Library webpage.
|
|
|
|
Using Software for Qualitative Analysis
February 4, 1:00 p.m. - 2:00 p.m.; 4218 Sewell Social Sciences. This course provides an insight into the general functionality of Qualitative Data Analysis software and will support researchers in confidently searching for a software tool that suits their research project and analysis workflow. We will discuss the promises of Qualitative Data Analysis (QDA) software, cautions, and general strategies for selecting a tool. Additionally, we will briefly introduce NVivo, MaxQDA, and Dedoose to compare and contrast their features and functionality. To learn more and register, visit the Using Software for Qualitative Analysis calendar listing and the Social Science Computing Cooperative webpage.
|
Python Programming: Introduction
February 4, 10:00 a.m. - 12:00 p.m.; Zoom. This workshop is for the absolute beginner wanting to slowly walk through getting started with Python, a programming language commonly used for data analysis. We’ll work through installation and setup of helpful software and introduce basic concepts and terminology used in Python. Finally, we’ll work together to create your first simple, but useful, program!
|
Visualizing Regression Results in R
February 4, 10:00 a.m. - 12:00 p.m.; 3218 Sewell Social Sciences. This workshop will teach you how to use ggplot2 and ggeffects to produce plots of predicted values for linear and logistic regression models. This workshop assumes you understand the basics of using the ggplot2 R package, as taught in Data Visualization in R: ggplot2 Basics, and how to fit regression models in R. To learn more and register, visit the Visualizing Regression Results in R calendar listing.
|
|
|
|
Exploring AI in Teaching: Critical AI Literacy
February 5, 12:00 p.m. - 1:00 p.m.; Zoom. Participants will engage with the ethical use of AI tools, potential biases in AI systems, implications for academic integrity, and strategies for integrating AI into writing assignments and activities in thoughtful, engaging ways. This session will provide a space for discussion and practical insights, empowering instructors to make informed decisions about incorporating AI while considering its challenges. Presented with Writing Across the Curriculum. To learn more and register, visit the Center for Teaching, Learning & Mentoring calendar listing.
|
|
|
|
Introduction to NVivo
February 5, 1:00 p.m. - 2:30 p.m.; 4218 Sewell Social Sciences. NVivo is a popular qualitative data analysis software that allows for organization, storage, coding, and analysis of any qualitative data including text, images, and video. This course will provide an introduction to the NVivo interface and teach you how to import data to NVivo, organize and coding data, perform analysis such as word counts and cross tabulation queries, and export query data. To learn more, visit the Introduction to NVivo calendar listing.
|
|
|
|
Functions and Iteration in R
February 6, 9:00 a.m. - 12:00 p.m.; 3218 Sewell Social Sciences. This workshop will teach you the basics of function writing to turn existing code procedures into functions, and return multiple and conditional values. We will then learn how to apply these functions we have written to series of data to perform tasks like calculating the standard error of each column in a dataframe, run simulations, and write and read files. We will also discuss how to parallelize iterative processes on the SSCC Slurm cluster.
|
|
|
|
Introduction to MaxQDA
February 6, 1:00 p.m. - 2:30 p.m.; 4218 Sewell Social Sciences. MaxQDA is a popular qualitative data analysis software that allows for organization, storage, coding, and analysis of any qualitative data including text, images, and video. This course will provide an introduction to the MaxQDA interface and teach you how to import data, organize your project, code data, perform analysis such as word counts and cross tabulation queries, and exporting query data. To learn more, visit the Introduction to MaxQDA calendar listing.
|
|
|
|
Loops and Macros in Stata
February 7, 1:00 p.m. - 3:00 p.m.; 4218 Sewell Social Sciences. Have you ever had to do the same thing to ten different variables and wished you didn't have to write it out ten times? If so, this workshop is for you. If you haven't experienced that, you will, so we recommend this workshop for anyone who anticipates using Stata regularly.
|
|
|
|
Have questions about anything data science-related? Come see the Data Science Hub facilitators at Coding Meetup on Tuesdays and Thursdays from 2:30-4:30 p.m. CT. To join Coding Meetup, join data-science-hubgroup.slack.com
|
|
|
|
SILO spring kickoff today: Efficiently Searching for Distributions
TODAY January 22, 12:30 p.m. - 1:30 p.m; Zoom and Orchard View Room, Discovery Building. Assistant Professor at the Department of Computer Sciences, Sandeep Silwal, will kick of the Spring 2025 SILO seminar series. How efficiently can we search distributions? Attend Professor Silwal's discussion to learn how the question is modeled. He will introduce a fresh perspective on the problem and study the relationship between sample complexity and time complexity. This question is particularly motivated as it is a generalization of the traditional nearest neighbor search problem: if we take enough samples, we can learn p explicitly up to low TV distance, and then find the closest v_i in o(k) time using standard nearest neighbor search. However, this approach requires Omega(n) samples.
Thus, it is natural to ask: can we obtain both sublinear number of samples and sublinear query time? Professor Silwal will present some nice progress towards this question and uncover a very interesting statistical-computational trade-off. For those who have not signed up to attend in-person, please refrain from taking pizza, as catering is arranged beforehand. For more information, view the full abstract from SILO's upcoming talks page.
|
|
|
|
ML4MI Seminar: Deep Generative Physical Modeling for MRI Reconstruction
January 28, 11:00 a.m. - 12:00 p.m; Zoom. Join Dr. Jon Tamir, Assistant Professor of Electrical and Computer Engineering at UT Austin, for a discussion about physical modeling for magnetic resonance imaging (MRI) reconstruction. Recently, deep learning techniques have been used as powerful data-driven reconstruction methods for inverse problems, and have led to reduced scan times in MRI. Typically, these methods are implemented using end-to-end supervised learning based on idealized imaging conditions. While promising, reconstruction quality is known to degrade when applied to natural measurement and anatomy perturbations.
In this talk Dr. Tamir will present an alternative approach to deep learning reconstruction based on distribution learning, in which his team trained a deep generative model to learn image priors without reference to the measurement process. He shows that decoupling the measurement and statistical models provides a powerful framework for MRI reconstruction. For more information and the Zoom link, visit the Machine Learning for Medical Imaging Learning Opportunities webpage.
|
|
|
|
ComBEE Monthly Event - AlphaFold
January 28, 3:00 p.m. - 4:00 p.m; Orchard View Room, Discovery Building. Join us for an engaging ComBEE talk exploring the fascinating world of protein language models, transformers, and the revolutionary advancements of AlphaFold. AlphaFold is an AI system that predicts protein 3D structure from amino acid sequence data. We'll dive into how these cutting-edge technologies are transforming our understanding of protein structures and their applications in science and medicine. The session will also include a hands-on demonstration of ColabFold, showcasing accessible tools and code to explore these innovations interactively. Whether you're a researcher, student, or just curious, this talk offers insights and practical takeaways for everyone!
|
|
|
|
Badgervoltaics™ Community Meeting
January 29, 3:30 p.m. - 5:00 p.m; Room 1153/1154, Discovery Building. Badgervoltaics™ is a community of practice that brings together students, researchers and industry professionals who share an interest in exploring the topic of agrivoltaics in Wisconsin. Agrivoltaics is a win-win solution where solar arrays are planned for multiple-uses in the same location.
|
|
|
|
ML+Coffee: Connect, Share, and Explore Machine Learning
February 12, 9:00 a.m. - 11:00 a.m.; Rm. 1145, Discovery Building. ML+Coffee offers a supportive and casual environment to discuss ongoing machine learning (ML) projects and share knowledge & tools across campus. Whether you're looking for advice on applying ML/AI to your data, hoping to demo a favorite tool, or interested in discussing an ML/AI paper, ML+Coffee offers the perfect space. All experience levels and backgrounds are welcome. Caffeinated beverages provided ☕ to keep the ideas flowing, courtesy of our sponsors.
The first spring event will be held on Wednesday, February 12, from 9:00 a.m. to 11:00 a.m. in Room 1145, Discovery Building, and we’re seeking two volunteers to kick us off by discussing an ongoing project (seeking feedback), showcasing an ML/AI tool, or discussing a paper. No formal presentation is required—this event prioritizes open dialogue over formal presentations. Use the ML+Coffee discussion/demo form to sign up for February 12 or later dates (March 5, April 2, and May 7). No matter your background, you’ll find a welcoming space to connect, learn, and share insights with the ML+X community.
|
|
|
|
Nexus Winter Challenge: Share ML/AI Resources and Win Prizes!
Nexus is the ML+X community’s website for crowdsourcing machine learning (ML) and AI resources —such as recorded talks, ML/AI libraries, genAI tools, model-use guides, datasets (e.g., for transfer learning), workshop materials, and more. Since launching in summer 2024, Nexus has quickly grown to feature 40 ML/AI resources in total — thanks, contributors! While this number is an impressive milestone, we'd love to see additional ML/AI practitioners contribute and fully leverage Nexus for their own needs/purposes. To incentivize additional contributions over winter, we are thrilled to offer a $50 Amazon gift card to whoever contributes the greatest number of resources by February 10th. This is only intended as an extra incentive, as the real prize is helping to build a stronger, more connected community of ML/AI practitioners on campus! Visit the How to Contribute page for detailed guidance on contributing. If you’re unsure about the scope (most submissions are accepted) or have other questions—please contact endemann@wisc.edu.
|
|
|
|
|
|
ShinyConf 2025
Proposals due February 2. Conference April 9 - 11; 7:00 a.m. - 3:00 p.m; Zoom. Join us for ShinyConf 2025, the biggest virtual Shiny event of the year hosted by our partner Appsilon! This free, fully virtual conference features a day of engaging workshops, two days of insightful talks, and innovative Shiny app showcases. Learn more and register now on the Shiny Conference website.
Shiny invites you to become a part of the conversation! Share your insights and expertise by submitting your talk proposals by February 2nd. The conference welcomes submissions on R and Python topics, covering everything from real-world Shiny apps to modern UI design. Your ideas can help make ShinyConf a vibrant, inclusive event, no matter your level of experience. Submit your ideas on the Shiny Conference Call for Speakers webpage.
|
|
|
|
Small Business Innovation Research (SBIR) and Small Business Technology Transfer (STTR): Proposal Preparation Intensive
|
|
|
|
Open Source Internship
Apply by January 27 - In collaboration with Madison College, the UW-Madison Open Source Program Office (OSPO) is establishing a new internship program for students to participate in open source software projects each semester. Undergrads and grad students with at least one semester left in their degree programs are eligible to apply. The internships have unique start and end dates, roughly beginning in February and ending in May.
Interns will learn crucial skills related to managing open-source software projects and growing software user communities. These paid internships are appropriate for students with a variety of experience levels, from those new to programming and open source to those who have more advanced skills. During the internships, students will join a mentored open-source project or develop a proposal for a self-directed project. They will participate in an initial training session and weekly check-ins with the Open Source Program Office.
Learn more about the program and how to apply on the OSPO website.
|
|
|
|
Research Computing Facilitation Intern
Apply by January 27 - UW-Madison’s Center for High Throughput Computing (CHTC) serves as the campus’s core research computing center. As part of our mission to share the potential of high throughput computing approaches with research fields, we host training events and undertake other facilitation activities like office hours and individual consultations.
|
|
|
|
Student Administrative Assistant
|
|
|
|
Corporate Sustainability Internship Program - Summer 2025
Apply by March 1 - The University of Wisconsin–Madison Corporate Sustainability Internship Program is a summer-long internship program that provides UW–Madison students with real-world sustainability experience in a corporate environment.
|
|
|
|
Computed Tomography (CT) Research Analyst
|
|
|
|
WIDA Data Integration Analyst
Apply by February 5 - The Data Integration Analyst position will be responsible for managing the data and synchronization between WIDA's core applications, including Salesforce CRM, Canvas LMS, Eloqua, and a custom developed WIDA Secure Portal. This position will be responsible for working with developers and other IT staff to define and design data sync processes between these critical systems and will provide continued support of these processes with monitoring and remediation of issues. Additionally, this role will create and support ad-hoc data loads and extracts in and out of our systems and develop custom reports and dashboards to present data to users. To learn more and apply, visit the WIDA Data Integration Analyst job posting.
|
Postdoctoral Position(s) Research Associate(s) in Dairy AI
Apply by February 28 - The Department of Animal and Dairy Sciences at the University of Wisconsin–Madison invites applications for one or two Postdoctoral Research Associate positions to lead advancements in artificial intelligence (AI) applications for sustainable and climate-smart dairy farm management.
This role will focus on applying Reinforcement Learning (RL) to optimize complex decision-making processes such as culling and replacement strategies by integrating economic, environmental, and animal welfare considerations and leveraging farm-specific data streams. The Research Associate will also leverage or extend modeling frameworks like the Ruminant Farm Systems (RuFaS) model to evaluate management scenarios, focusing on actionable outcomes such as improving diets, manure management, and cropping systems to enhance economic viability, environmental sustainability, and overall farm productivity. For more information and to apply, visit the Postdoctoral Research Associate job posting.
|
|
|
|
|
|
|
DATA VISUALIZATION OF THE WEEK
|
|
|
|
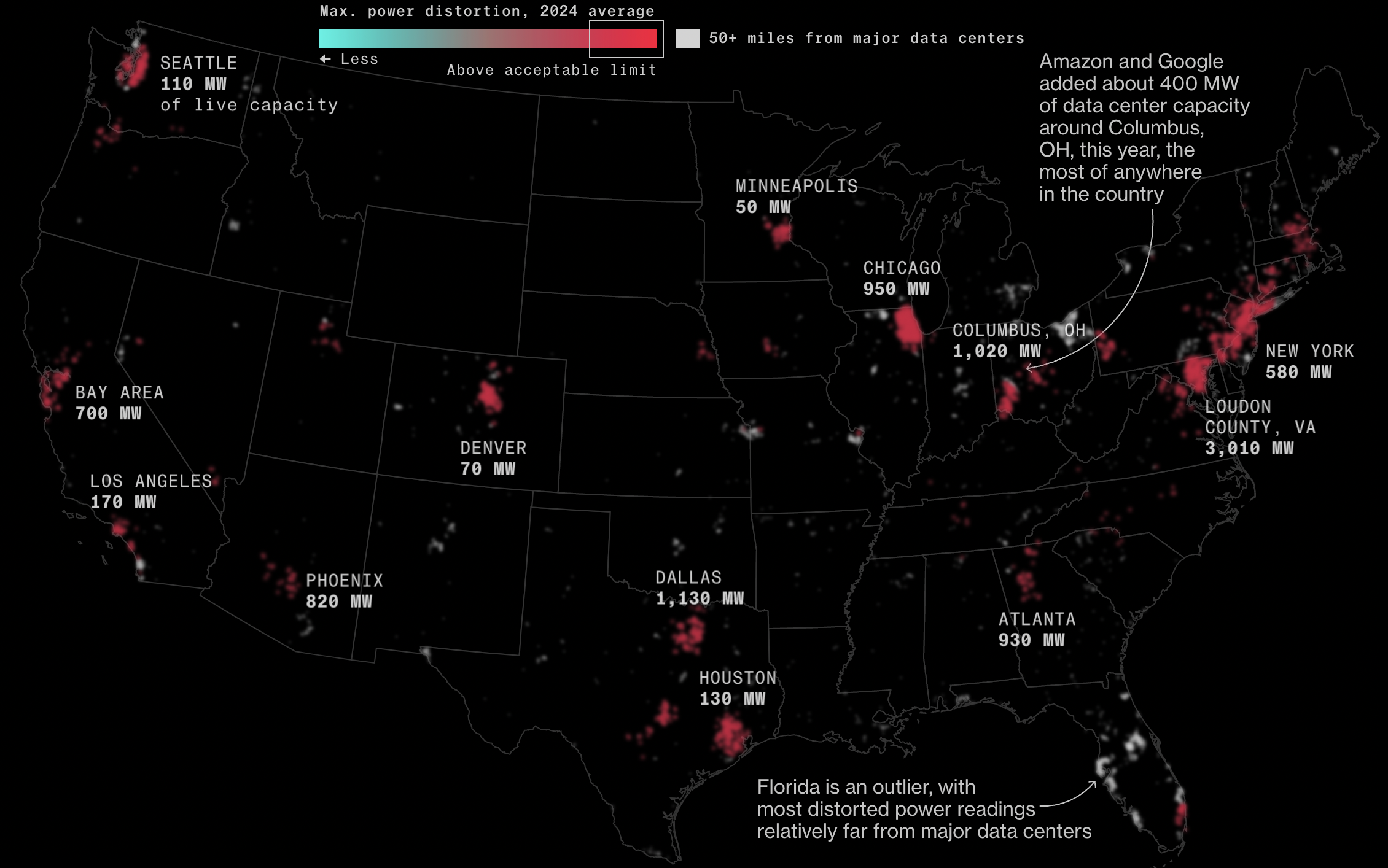
AI Needs So Much Power, It's Making Yours Worse
Below is a visualisation created by Leonardo Nicoletti, Naureen Malik, and Andre Tartar for Bloomberg Technology. Data from Whisker Labs and consumers across the US show that "AI data centers are multiplying across the US and sucking up huge amounts of power. New evidence shows they may also be distorting the normal flow of electricity for millions of Americans." Data center energy demand is straining electricity supplies, raising concerns over price hikes and outages, a situation expected to worsen as more data centers are built. This strain can also degrade power quality, damaging appliances, increasing fire risks, and leading to brownouts, blackouts, and voltage surges.
"The problem is threatening billions in damage to home appliances and aging power equipment, especially in areas like Chicago and "data center alley" in Northern Virginia, where distorted power readings are above recommended levels." The map below shows readings from about 770,000 home sensors, with red zones indicating areas with the most distorted power. Read the full Bloomberg article to learn more.
|
|
|
|
Data Science Updates is a collaborative effort of the Data Science Institute and Data Science Hub.
Use our submission form to send us your news, events, opportunities and data visualizations for future issues.
|
|
|
|
|