Data Science Updates is the University of Wisconsin-Madison's resource for news, training, events, and professional opportunities in data science, brought to you by the Data Science Institute, powered by American Family Insurance, and the Data Science Hub.
July 16, 2025
|
|
|
|
Scientific researchers need reproducible software environments for complex applications that can run across heterogeneous computing platforms. Reproducible Machine Learning Workflows for Scientists is a free, hands-on workshop for researchers of all levels that will provide a practical introduction to using Pixi, an open source tool well-suited for research. Learn to create fully reproducible, hardware-accelerated environments for scientific and AI/ML workflows in this workshop at UW–Madison, August 12-14. Register by this Friday, July 18.
|
|
|
|
Chris Endemann Joins the DoIT Research Cyberinfrastructure Team
After four years at the Data Science Hub—where he built the ML+X community and launched new AI-focused workshops—Chris Endemann has joined DoIT’s Research Cyberinfrastructure (RC) group as a consultant helping researchers apply AI and cloud tools in their work.
|
|
|
|
“I'm extremely grateful to have contributed to the Hub's mission and to have been part of a team dedicated to advancing research and building community on campus,” says Endemann. “In this new role, my core mission of helping researchers leverage ML and AI remains the same. I'll be building and supporting secure, scalable cloud environments for AI/ML workflows, running cloud- and AI-focused workshops, and collaborating closely with campus partners to scale up research computing capabilities. I’ll also continue leading ML+X in collaboration with the Hub. The Machine Learning Marathon will also live on—stay tuned for registration details in August!”
Thank you, Chris, for your contributions to the Data Science Hub and Data Science @ UW!
|
|
|
|
Anthony Gitter designs novel computational methods to study diseases, particularly viral infections and cancer, and develop new drugs and proteins. A core problem in biology is understanding how cells respond to changes. Gitter’s team creates algorithms to trace messages passed between networks of biomolecules within cells; for example, to understand what happens when human cells are infected with viruses. His lab also develops machine learning models to dramatically speed up the process of drug discovery, collaborating with domain scientists to target the most promising chemicals for lab experiments. Learn about his work in Faces of Data Science.
|
|
|
|
July 18, 9:00 a.m. - 12:00 p.m.; 3218 Sewell Social Sciences Building. In this workshop, you'll learn how to make a set of real-world tables requested by real-world researchers using Stata's table and collect commands. You'll learn some new tricks and gain experience with these powerful and flexible tools.
|
|
|
|
July 23, 1:00 p.m. - 1:45 p.m.; 4218 Sewell Social Sciences Building. This workshop will show you how to use the SSCC's Linux servers for your research, including Linstat and Slurm. It is designed for a small group, and the agenda will be flexible, depending on the participants' needs, interests, and backgrounds. Topics may include moving your data to the SSCC file system, modifying your code so it will run on the servers, running programs, like R, Stata, Python, etc, and running jobs that use GPUs.
|
|
|
|
July 30-31, 9:00 a.m. - 2:00 p.m.; Orchard View Room, Discovery Building. This workshop provides a beginner-friendly overview of machine learning (ML) and common ML methods— including regression, classification, clustering, dimensionality reduction, ensemble methods, and a quick neural-network demo—using Python + scikit-learn. The broad coverage will jump-start your ML journey and point you toward the next learning steps. Participants should be comfortable with core Python (loops, functions, NumPy), but no prior ML experience is required. Register by July 25.
|
|
|
|
August 4-7 and 11-12, 9:00 a.m. - 1:00 p.m.; Zoom. Data Carpentry aims to teach researchers basic concepts, skills, and tools for working with data to get more done in less time and with less pain. This workshop teaches data management and analysis for genomics research, including: best practices for organization of bioinformatics projects and data, use of command-line utilities, use of command-line tools to analyze sequence quality and perform variant calling, connecting to and using cloud computing, and using R for analysis.
|
|
|
|
August 25-28, 9:00 a.m. - 12:30 p.m.; Discovery Building, Orchard View Room. In this three-day, half-day workshop, students will learn tools and practices for producing and sharing quality, sustainable, and FAIR (Findable, Accessible, Interoperable and Reusable) research software to support open and reproducible research. The target audience is graduate students and early career researchers or Research Software Engineers (RSEs) who are starting their research or software projects; have foundational knowledge of Python, version control, and using software tools from command line shell; and want to develop software to support their research using established best practices. It is also a great refresher for experienced researchers.
|
|
|
|
August 25, 10:00 a.m. - 3:00 p.m.; 3218 Sewell Social Sciences Building. This workshop introduces the basics of the RStudio interface and the R language, with topics including creating and running scripts, saving your work, using functions, and installing packages. There will be opportunities to apply what we learn during class time.
|
|
|
|
August 25, 10:00 a.m. - 3:00 p.m.; 4218 Sewell Social Sciences Building. In this class, you'll learn the basics of Stata. This class (or comparable experience) is a prerequisite for the rest of SSCC's Stata training. It will also prepare you to excel in classes that use Stata, like Sociology 361 or Economics 410. We suggest new graduate students consider taking this class before or during their first semester.
|
|
|
|
August 26-29, 10:00 a.m. - 3:00 p.m.; 3218 Sewell Social Sciences Building. "Data wrangling" is the process of preparing data for analysis. This is a hands-on class with time devoted to practicing essential data wrangling skills. This course will first cover the tools needed to work with different data types. Then we will apply these tools in the context of datasets to create, transform, and clean variables. We will also restructure datasets by taking subsets, combining multiple datasets, summarizing datasets, and changing how datasets are organized.
|
|
|
|
August 26-28, 10:00 a.m. - 3:00 p.m.; 3218 Sewell Social Sciences Building. Data wrangling is a critical skill for research. In this class, you'll learn how to wrangle data using Stata. We'll cover some key concepts and workflows of data science and the structure and logic of Stata. We'll emphasize real-world issues like handling missing data, checking for errors, and best practices for research computing and reproducibility. Our goal is to give you a strong foundation you can build on to become an expert data wrangler.
|
|
|
|
Have questions about anything data science-related? Come see the Data Science Hub facilitators at Coding Meetup on Tuesdays and Thursdays from 2:30-4:30 p.m. CT. To join Coding Meetup, join data-science-hubgroup.slack.com.
|
|
|
|
SILO: Robust Clustering and Testing for Large Complex Networks Using Rank Statistics
TODAY July 16, 4:00 p.m. - 5:00 p.m.; Memorial Union - Council Room (4th Floor). Joshua Cape, Assistant Professor of Statistics at the University of Wisconsin–Madison, presents new methods and theory for robust spectral clustering and hypothesis testing in large, edge-weighted random graphs using rank statistics.
|
|
|
|
July 18-19, 911 Van Vleck Hall. This event aims to include both talks in which algebra is used to tackle applied problems and provide new understanding, as well as talks in which an area of application is laid out that may be amenable to algebraic methods.
|
|
|
|
Applications due August 1. CHR&R invites original visualizations using CHR&R data to show how laws, policies, and power structures shape health. Individuals or teams can submit static or interactive visuals and a 250–500 word description by August 1. Submissions will be judged on relevance, clarity, design, and creativity. Winners, announced August 8, may be featured online and invited to collaborate.
|
|
|
|
August 11, 10:30 a.m. - 3:30 p.m.; Discovery Building. The GSTP aims to train the new biologists, enabling them to gain strengths by bridging multiple disciplines needed for an integrated approach to solving complex problems in genomics research. The GSTP Annual Retreat will include faculty and trainee talks and a poster session.
|
|
|
|
|
|
|
DATA VISUALIZATION OF THE WEEK
|
|
|
|
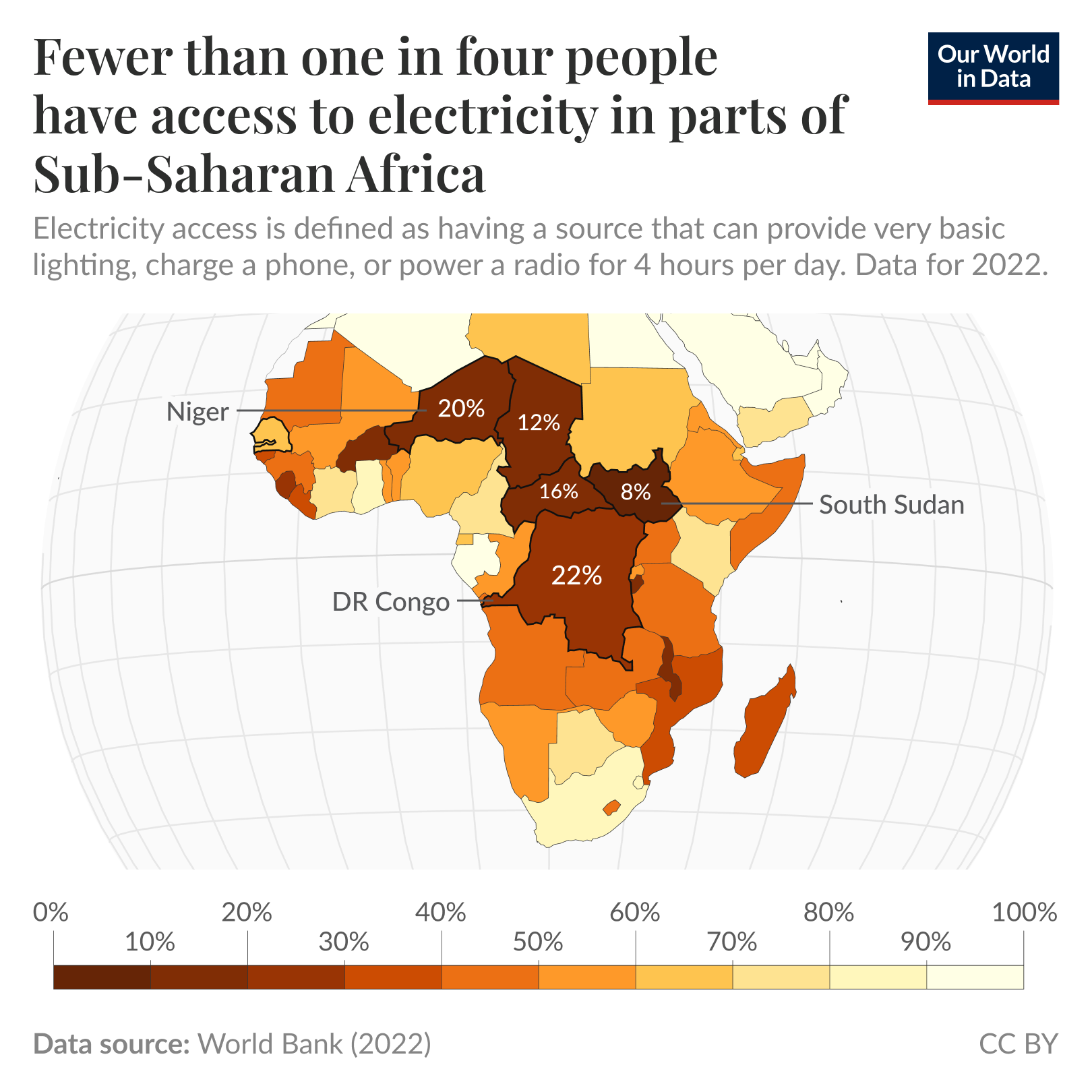
Life without electricity is a reality for millions in Sub-Saharan Africa. This map shows the share of people with access to electricity across the region. This is defined as having a source that can provide basic lighting, charge a phone, or power a radio for just 4 hours daily.
In Chad, only 12% of people have electricity access. In the Democratic Republic of Congo — a country of over 100 million people — it's just 22%. Overall, 85% of people worldwide who lack access to electricity now live in Sub-Saharan Africa. There are bright spots, though. Countries like Kenya, where more than three-quarters of people now have electricity, show that progress in the region is possible.
|
|
|
|
Data Science Updates is a collaborative effort of the Data Science Institute and Data Science Hub. This newsletter was originally created by the Data Science Hub and published as Hub Updates.
Use our submission form to send us your news, events, opportunities and data visualizations for future issues.
|
|
|
|
|